3-Node Hyperconverged Ceph/OpenStack Cluster

Overview
This is a rough documentation of my OpenStack private cloud build for hosting my lab and other home services. I’m coming at this from zero experience in OpenStack, KVM, and Ceph. I’ve been learning this stuff pretty intensively for the last 3 months. My previous experience has all been in Microsoft Hyper-V and VMWare vSphere and I have moderate level Linux skills, so I’m by no means and expert, I’m just giving it a go.
These are mainly just notes for my own reference, rather than a full guide, but I’m sharing it for anyone else who might want to build something similar. Reach out if there’s anything you want me to clarify or expand on. Or if you spot something I’m doing wrong.
This was my 4th build from scratch. Each time I refined my notes a little more. Ideally such a solution should be deployed with Ansible or similar and I might get to that but for learning I think doing it all by hand is best.
I was advised that OpenStack and Ceph were too complex and too resource intensive for this kind of build, but I’ve been pleasantly surprised just how well this thing runs. E.g. 21k IOPS of 4K random write, 80k 4k random read from within the VMs. With that said, I haven’t loaded it up yet with a lot of VMs yet. I’m hoping to be able to run about 50 VMs of various sizes.
Disclaimer - I’m not very skilled in storage or disk performance so I just tried a bunch of different fio(Linux) and diskspd (Windows) tests until I got an impressive looking screenshot from the Ceph dashboard. The screenshot below is from diskspd -c100b -b4K -o32 -F8 -T1b -s8b -W60 -d60 -Sh testfile.dat
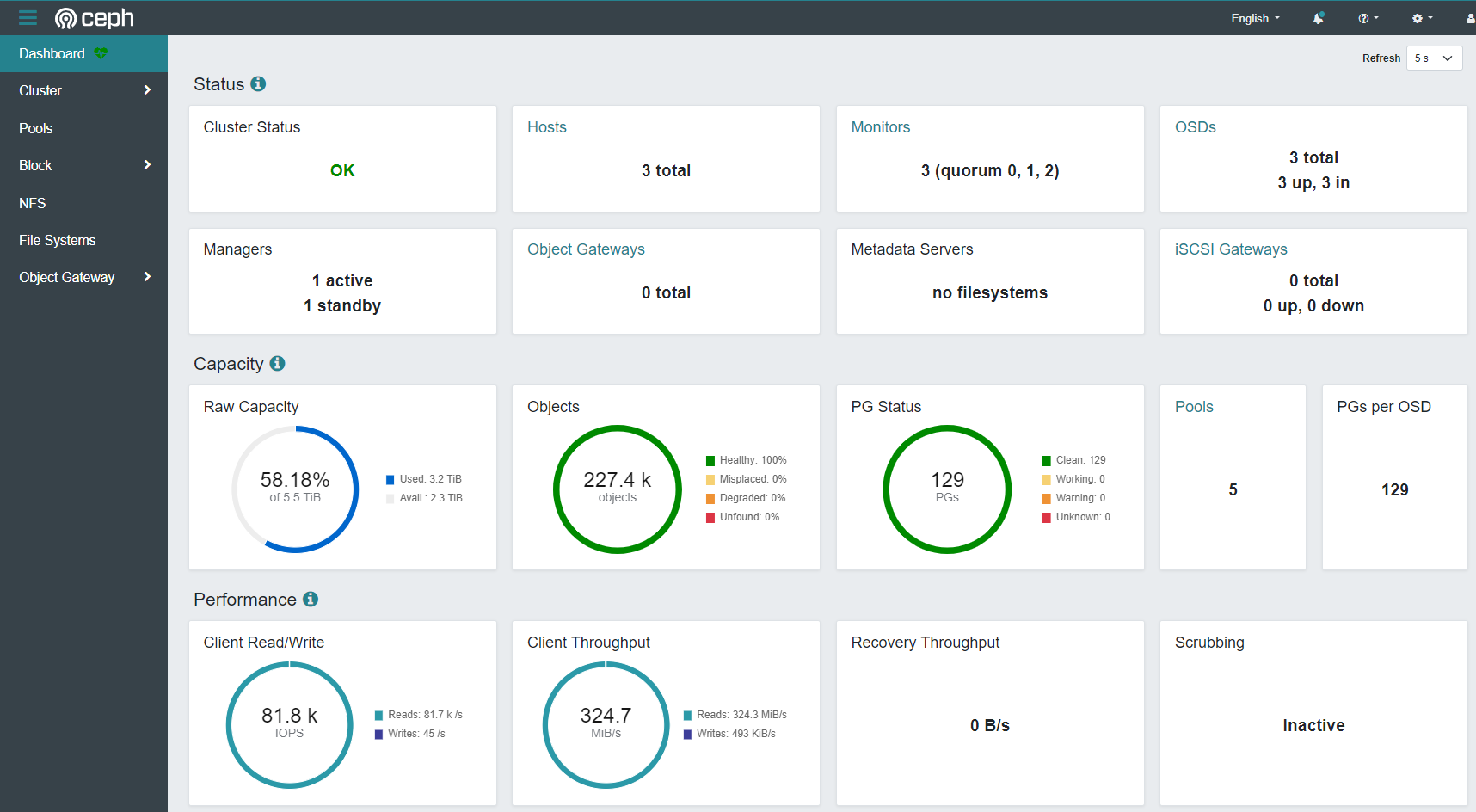
And of course, what good is a lab if it can’t keep your linen closet warm and dry?







Solution Overview
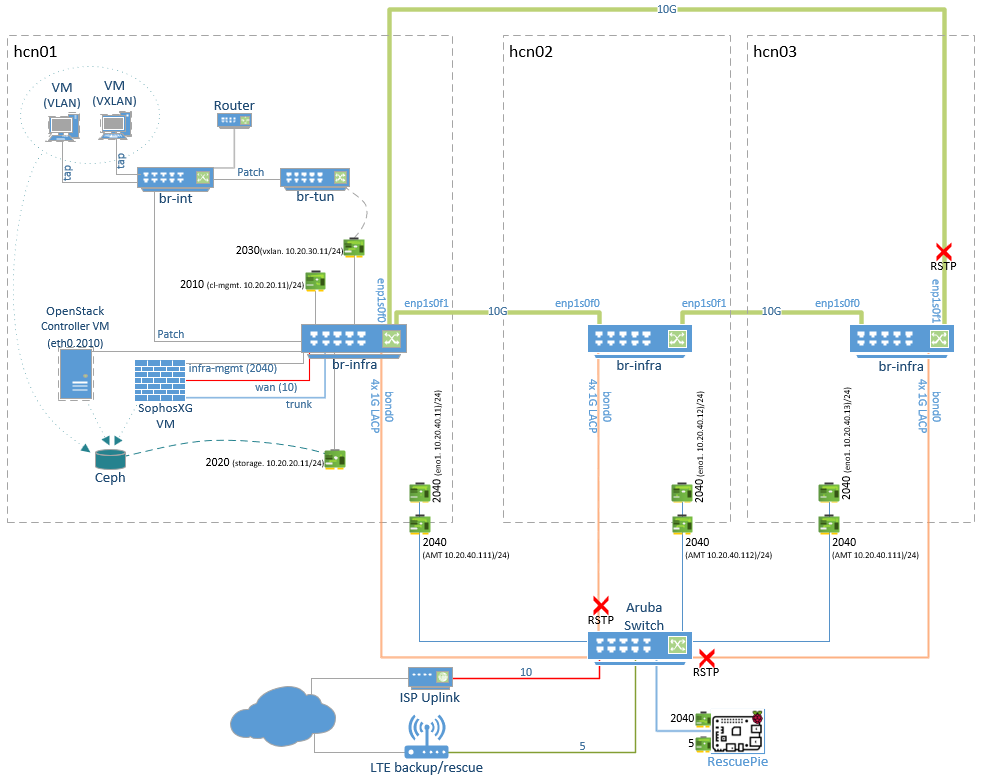
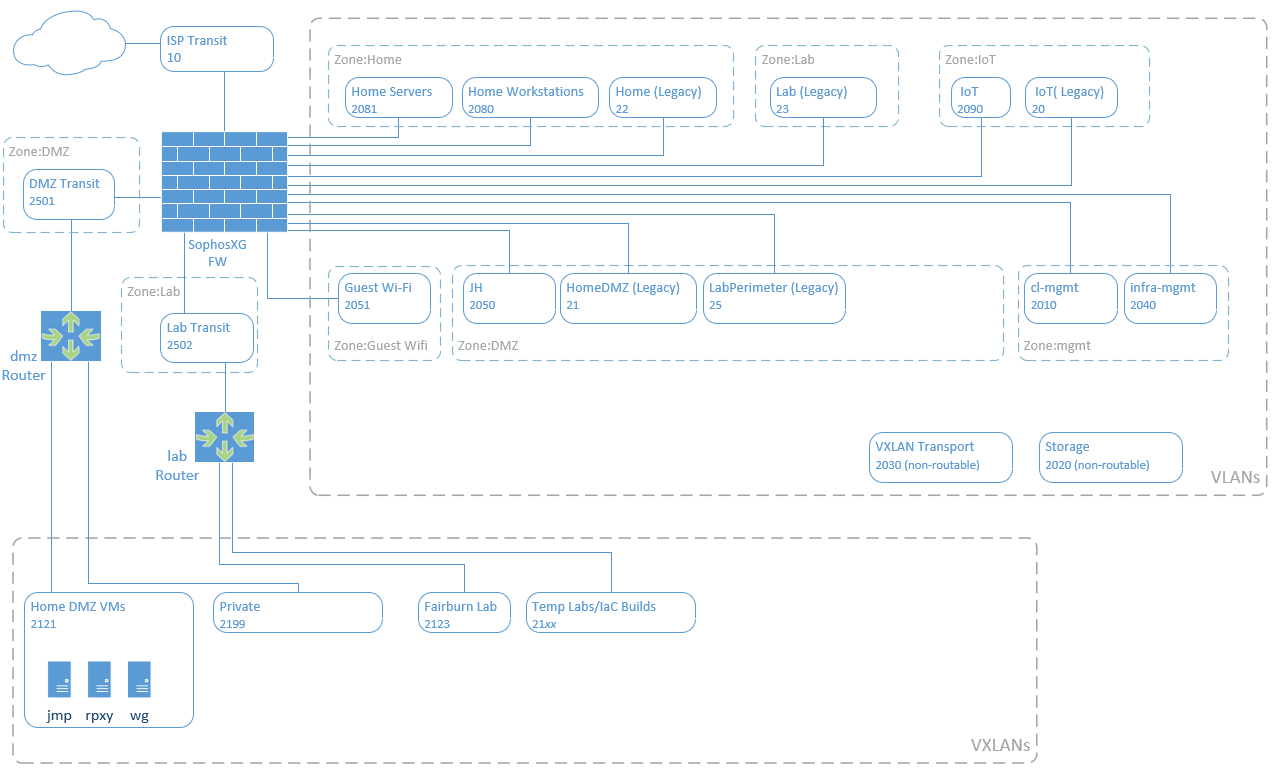
- Each node (hcn01, hcn02, hcn03) is identical. In the diagram I’ve only shown the detail for hcn01
- The OpenStack controller VM and the and the firewall VM live on the storage cluster but outside of OpenStack as simple libvirt KVM VMs. These can be live migrated between hosts as needed for maintenance etc.
Logical Network
Project Goals
- Eliminate (or at least minimise) single points of failure
- Max 3 hosts - hence integrated storage and compute (hyper-converged)
- Sustain operation in event of full host failure
- Learn about OpenStack, Ceph and software defined networking
- Use Terraform for managing resources
- 10G for cluster networking (No 10G switch, ring topology)
- Keep the linen dry
Hardware (Each node, three nodes)
- Hp Elitedesk G5 Small Form Factor
- Intel i7-9700 (8 Cores)
- 64GB DDR4 (Expandable to 128GB)
- Broadcom Quad 1G NIC
- Intel X520 Dual 10G NIC (SFP+)
- 256GB SATA SSD (OS)
- 2TB Samsung 980 Pro NVME (Ceph OSD)
- 2TB Samsung 870 EVO SATA (Ceph OSD)
- 1 spare SATA and 1 Spare NVME for expansion
Hosts and Interfaces
All hosts are running ubuntu 22.04 LTS
hcn01
First hyper-converged node. This is where the OpenStack controller VM will be built, it will be the primary for DNS and the central point for NTP but otherwise should end up pretty much identical to the hcn02 and hcn03
- infra-mgmt. IP: 10.20.40.11/24 (VLAN: 2040)
- cl-mgmt. IP: 10.20.10.11/24 (VLAN: 2010)
- storage IP: 10.20.20.11/24 (VLAN: 2020)
- vxlan IP: 10.20.30.11/24 (VLAN: 2030)
hcn02
Second hyper-converged node
- infra-mgmt. IP: 10.20.40.12/24 (VLAN: 2040)
- cl-mgmt. IP: 10.20.10.12/24 (VLAN: 2010)
- storage IP: 10.20.20.12/24 (VLAN: 2020)
- vxlan IP: 10.20.30.12/24 (VLAN: 2030)
hcn03
Third hyper-converged node
- infra-mgmt. IP: 10.20.40.13/24 (VLAN: 2040)
- cl-mgmt. IP: 10.20.10.13/24 (VLAN: 2010)
- storage IP: 10.20.20.13/24 (VLAN: 2020)
- vxlan IP: 10.20.30.13/24 (VLAN: 2030)
hcc01
OpenStack Controller VM, running as a libvirt KVM VM outside of OpenStack, Stored on the Ceph cluster
- cl-mgmt. IP: 10.20.10.10/24 (VLAN: 2010)
hcui01
OpenStack Skyline dashboard VM running in OpenStack
- cl-mgmt. IP: 10.20.10.5/24 (VLAN: 2010)
10G Ring Topology
This is something I’ve always wanted to try. To avoid the need for a 10G switch the hosts are all connected to each other with a dual Intel X520 10Gb NICs using DAC cables. With Open vSwitch with RSTP enabled this works very well. Just don’t stop the Open vSwitch service on a host as this creates a wild broadcast storm which brings the entire network to its knees and sets the CPUs to 100%! Not sure if/how this can be mitigated should the Open vSwitch service crash, but so far, no issues.
Question: In theory it should be possible to use OpenFlow to control Open vSwitch rather than using RSTP which introduces the penalty of an extra hop for one of the noes. As per the diagram below, host hcn03 must go via hcn02 to reach hcn01. **Does anyone know how to set this up purely with Openflow?
Uplink Bond
Each node has 4 1G NICs on a quad port card which are configured in an LACP bond to provide an uplink to the physical switch. Again, RSTP is enabled on the physical switch to prevent loops.
High-level Build Steps
- Prepare hardware
- Update BIOS/firmware
- Set identical BIOS settings across all hosts
- Configure Intel ME AMT for out-of-band console
- Build base OS (Ubuntu 22.04)
- Configure chrony time sync
- Configure passwordless root between nodes
- Install and configure bind DNS (We want to use FQDNs for most things)
- Configure host networking
- Create open vSwitch bridges and host interfaces
- Install Ceph and bootstrap cluster
- Create VM for OpenStack controller VM:
- Configure libvirt/KVM to work with Ceph
- Create Ceph pool and image
- Deploy controller VM
- Install and Configure OpenStack
- Configure controller VM
- Configure physical compute nodes
- Create Dashboard VM in OpenStack
- Install and configure Skyline Dashboard
Host Build
Note: Connecting to Intel AMT KVM in >S0 power state causes NIC to be at 10Mbps. Known issue, comes back to 1G after reboot. Workaround by connecting to console after power-up.
Install Ubuntu 22.04 from USB [All Nodes]
- For the Intel AMT console to work during the installer we need to edit grub boot options at the installer grub menu by pressing ‘e’ to add nomodeset after “vmlinuz” on the “linux” line.
- Add static IP for the infra-mgmt interface on 10.20.40.0/24
- default route and DNS pointing to the main firewall for internet access
Persist nomodeset [All Nodes]
- Configure the onboard 1G NIC for initial management and enable SSH
- After the install configure nomodeset in the grub config
- Edit /etc/default/grub:
- Set
GRUB_CMDLINE_LINUX_DEFAULT="nomodeset" - update-grub
- reboot
- Set
Set hostname [All Nodes]
- Make sure the hostname is not the FQDN
hostnamectl set-hostname hcn01 - Edit /etc/hosts add the bare and FQDN hostname
- Remove the bare host name pointing to 127.0.0.1
127.0.0.1 localhost
10.20.10.11 hcn01.i.rhysmg.nz hcn01
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
- Check with
hostname&hostname -f
Update [All Nodes]
apt update apt upgrade
Bind DNS
We want to have a dedicated domain name and use FQDNs for all our services within the cluster. This also allows us to generate let’s encrypt certificates to secure our services with TLS. Bind9 will be used and hcn01 will be the primary and hcn02 and hcn03 will be secondary. I won’t go into much detail here, there are plenty of guides out there for setting up bind. I might come back later and implement this so that it’s easy to switch primary/secondary around.
Install bind on all three nodes: apt install bind9 bind9utils
hcn01 (Primary)
Configure global options /etc/bind/named.conf.options:
acl "trusted" {
10.20.10.0/24; #Cl-mgmt network
};
options {
directory "/var/cache/bind";
recursion yes; # enables recursive queries
allow-recursion { trusted; }; # allows recursive queries from "trusted" clients
listen-on { 10.20.10.11; }; # private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
forwarders {
8.8.8.8;
8.8.4.4;
};
};
Include a conf file to define our zone(s) in /etc/bind/named.conf: include "/etc/bind/named.conf.mydomains";
Define the infrastructure zone in /etc/bind/named.conf.mydomains:
zone "i.rhysmg.nz" {
type primary;
file "/etc/bind/db.i.rhysmg.nz";
allow-transfer { 10.20.10.11; 10.20.10.12; 10.20.10.13;};
notify yes;
};
Define the infrastructure zone in /etc/bind/db.i.rhysmg.nz:
$TTL 604800
@ IN SOA hcn01.i.rhysmg.nz. admin.i.rhysmg.nz. (
11 ; Serial
604800 ; Refresh
86400 ; Retry
2419200 ; Expire
604800 ) ; Negative Cache TTL
;
IN NS hcn01.i.rhysmg.nz.
IN NS hcn02.i.rhysmg.nz.
IN NS hcn03.i.rhysmg.nz.
hcui01.i.rhysmg.nz. IN A 10.20.10.5
hcc01.i.rhysmg.nz. IN A 10.20.10.10
hcn01.i.rhysmg.nz. IN A 10.20.10.11
hcn02.i.rhysmg.nz. IN A 10.20.10.12
hcn03.i.rhysmg.nz. IN A 10.20.10.13
hcn02 & hcn03 (Bind secondary)
Configure global options /etc/bind/named.conf.options:
acl "trusted" {
10.20.10.0/24; #Cl-mgmt network
};
options {
directory "/var/cache/bind";
recursion yes; # enables recursive queries
allow-recursion { trusted; }; # allows recursive queries from "trusted" clients
listen-on { 10.20.10.12; }; # private IP address - listen on private network only
allow-transfer { none; }; # disable zone transfers by default
dnssec-validation no;
forwarders {
10.20.10.254; # Main Firewall/DNS server which hosts other zones in the network
};
};
Include a conf file to define our zone(s) in /etc/bind/named.conf: include "/etc/bind/named.conf.mydomains";
Define the infrastructure zone in /etc/bind/named.conf.mydomains:
zone "i.rhysmg.nz" {
type secondary;
file "db.i.rhysmg.nz";
masters { 10.20.10.11;};
};
On all hosts: systemctl restart bind9
At this point I established DNS forwarding from my main DNS server for the i.rhysmg.nz domain so I can use names from my management workstation. We’ll configure our hosts to use their own DNS service in the next step.
Networking [All Nodes]
Netplan
Create a new netplan (this example is for hcn03)
rm /etc/netplan/00-installer-config.yaml
vi /etc/netplan/00-hcn.yaml
network:
ethernets:
eno1:
addresses:
- 10.20.40.13/24
routes:
- to: default
via: 10.20.40.254
nameservers:
addresses: [10.20.40.254]
cl-mgmt:
dhcp4: false
addresses: [10.20.10.13/24]
storage:
dhcp4: false
addresses: [10.20.20.13/24]
vxlendpoint:
dhcp4: false
addresses: [10.20.30.13/24]
enp1s0f0: {}
enp1s0f1: {}
enp3s0f0: {}
enp3s0f1: {}
enp3s0f2: {}
enp3s0f3: {}
bonds:
bond0:
interfaces:
- enp3s0f0
- enp3s0f1
- enp3s0f2
- enp3s0f3
parameters:
lacp-rate: fast
mode: 802.3ad
transmit-hash-policy: layer2
version: 2
netplan apply
Interfaces
- eno1 is the 1G onboard NIC on native VLAN 2040 (infra-mgmt). We use this for initial setup/mgmt. but it will ultimately be used as an emergency mgmt. interface should the host become inaccessible on the main cl-mgmt interface. e.g. if there was an issue with the Open vSwitch.
- cl-mgmt for general cluster communication. This is the main interface for the host.
- storage is for Ceph backend storage replication traffic
- vxlendpoint is transport for VXLAN software defined self-service networks Note: cl-mgmt, storage, and vxlendpoint are defined above although they don’t exist yet. They will be created as internal interfaces on the Open vSwitch bridge.
- There are firewall interfaces in the cl-mgmt and infra-mgmt VLANs for internet/DNS services
- The 4x 1Gb NICs on the Broadcom card are added to an LACP (802.3ad) bond and the physical HP switch has matching config
- Neither the bond nor the two 10G NICs have IP addresses they are just for physical uplinks in the Open vSwitch as below
Open vSwitch
apt install openvswitch-switch
br-infra vSwitch
This is the main vSwitch for physical connectivity both between the other hosts in the 10G ring topology and uplink to the physical switch via the 4x1Gb bond.
NOTE: enabling RSTP on this switch and the physical switch is critical, otherwise you’ll end up with a wicked 10G broadcast storm. This must be done before adding any physical interfaces (ask me how I know).
The RSTP priority of the vSwitch on each node is set lower (higher precedence) than the physical switch to ensure traffic which can stay within the 10G ring does so
Virtual interfaces cl-mgmt, storage, and vxlendpoint are created from this bridge as virtual internal interfaces on the host OS
ovs-vsctl add-br br-infra
ovs-vsctl set Bridge br-infra rstp_enable=true other_config:rstp-priority=8192
ovs-vsctl add-port br-infra cl-mgmt tag=2010 -- set interface cl-mgmt type=internal
ovs-vsctl add-port br-infra storage tag=2020 -- set interface storage type=internal
ovs-vsctl add-port br-infra vxlendpoint tag=2030 -- set interface vxlendpoint type=internal
ovs-vsctl add-port br-infra enp1s0f0
ovs-vsctl add-port br-infra enp1s0f1
ovs-vsctl add-port br-infra bond0
systemctl restart openvswitch-switch
ovs-vsctl show
ovs-appctl rstp/show
Update Netplan
Update the netplan on all nodes and put the default route and the nameservers on the cl-mgmt IP. From now on we’ll be using the cl-mgmt interface for management, the infra-mgmt interface is only for emergency.
Note that I have used a policy-based route on the infra-mgmt interface (eno1). It has its own default gateway to avoid asymmetric routing.
The first nameserver points to itself and the other nodes as second and third.
The updated netplan example is for hcn03
network:
ethernets:
eno1:
addresses:
- 10.20.40.13/24
routes:
- to: 10.20.40.0/24
scope: link
table: 100
- to: default
via: 10.20.40.254
table: 100
routing-policy:
- from: 10.20.40.13/32
table: 100
cl-mgmt:
dhcp4: false
addresses: [10.20.10.13/24]
routes:
- to: default
via: 10.20.10.254
nameservers:
addresses:
- 10.20.10.13
- 10.20.10.12
- 10.20.10.11
search:
- i.rhysmg.nz
storage:
dhcp4: false
addresses: [10.20.20.13/24]
vxlendpoint:
dhcp4: false
addresses: [10.20.30.13/24]
enp1s0f0: {}
enp1s0f1: {}
enp3s0f0: {}
enp3s0f1: {}
enp3s0f2: {}
enp3s0f3: {}
bonds:
bond0:
interfaces:
- enp3s0f0
- enp3s0f1
- enp3s0f2
- enp3s0f3
parameters:
lacp-rate: fast
mode: 802.3ad
transmit-hash-policy: layer2
version: 2
Chrony NTP
Time sync is of course critical to the operation of several components in the cluster, especially storage. I’ve found chrony to be reliable and super simple to configure. I prefer to use FQDNs for most things, but for something as critical as time sync I prefer to take DNS out of the picture.
Install chrony on all hosts:
apt install chrony
hcn01 goes out to the internet for NTP, hcn02 and hcn3 point to hcn01:
Add this to hcn01:
#Allow local clients on the cl-mgmt vlan
allow 10.20.10.0/24
On the other two nodes comment out the default pool/servers and add the cl-mgmt IP of hcn01
server 10.20.10.11 iburst
Check each host with chronyc sources
Passwordless root between hosts
I use one shared SSH key pair for root on all nodes, you might prefer a separate pair for each
- On hcn01 create a key pair with
ssh-keygen -t ed25519 -C "root shared"(no passphrase) - Add the public key to authorized_keys:
cat /root/.ssh/id_ed25519.pub >>/root/.ssh/authorized_keys - On the other two nodes manually add the public key to /root/.ssh/authorized_keys
- On hcn01 copy the entire root .ssh directory to the other two hosts
scp -r /root/.ssh hcn02:/root/ scp -r /root/.ssh hcn02:/root/ - From each host SSH to the other two hosts to confirm passwordless root ssh is working
Ceph
Now we get to the fun bit…I’m running Ceph Quincy 17.2.6. 18.2.0 is just released but not packaged yet for Ubuntu 22.04
If needed clean up OSD disks on all hosts from previous builds
lvm lvdisplay
lvm vgremove ceph-be76f71f-d88b-4f58-af5a-1ec904ace250
wipefs -a /dev/nvme0n1
Install cephadm on all hosts
apt install -y cephadm ceph-common
On hcn01 create a cephbootstrap.conf config file:
[global]
public_network = 10.20.10.0/24
cluster_network = 10.20.20.0/24
bootstrap the cluster from hcn01:
cephadm bootstrap --config cephbootstrap.conf --mon-ip 10.20.10.11
NOTE: Capture the initial dashboard admin password from the console
Copy the Ceph SSH key to the other two hosts:
ssh-copy-id -f -i /etc/ceph/ceph.pub root@hcn02
ssh-copy-id -f -i /etc/ceph/ceph.pub root@hcn03
Add the other hosts to the cluster:
ceph orch host add hcn02 --labels _admin
ceph orch host add hcn03 --labels _admin
Set memory for ceph: (i.e. 64Gb x 0.1 = 6.4 GB). This maybe too low but I’ll see ho wit goes
ceph config set mgr mgr/cephadm/autotune_memory_target_ratio 0.1
ceph config set osd osd_memory_target_autotune true
Add all OSDs:
ceph orch apply osd --all-available-devices
Go take a look in the webui to see that OSDs have been created https://hcn01.i.rhysmg.nz:8443/. Continue once all three OSDs are online.
Allow pools to be deleted. Maybe turn this off again later.
ceph config set mon mon_allow_pool_delete true
Check the OSDs are on the cluster network:
ceph osd metadata 0 | grep addr
Set the class for the NVME disks:
ceph osd crush rm-device-class osd.0
ceph osd crush rm-device-class osd.1
ceph osd crush rm-device-class osd.1
ceph osd crush set-device-class nvme0 osd.0
ceph osd crush set-device-class nvme0 osd.1
ceph osd crush set-device-class nvme0 osd.2
Create a crush rule for this set of disks:
ceph osd crush rule create-replicated replicated_rule_nvme0 default host nvme0
NOTE: Ceph will report packet drops on the br-int interface. Apparently this is because this interface is down therefor drops broadcast packets as expected, so this alarm can be safely ignored: https://platform9.com/kb/openstack/br-int-packet-loss-observed
Libvirt / Ceph [All Nodes]
In this step we set up libvirt to work with Ceph so that we can create the OpenStack Controller VM on the storage cluster but outside of OpenStack
First we install all the required packages, then create a Ceph pool to place non-openstack-managed VMs and a user/secret which libvirt will use to access this pool. Then we configure libvit to use the pool
Install libvirt packages:
apt install qemu-kvm libvirt-daemon-system libvirt-clients bridge-utils virtinst libvirt-daemon-driver-storage-rbd -y
#apt install libvirt-daemon-driver-storage-rbd -y
systemctl restart libvirtd
On hcn01 setup libvirt for Ceph Access.
Credit: https://blog.modest-destiny.com/posts/kvm-libvirt-add-ceph-rbd-pool/
export CEPH_PGS="128"
export CEPH_USER="libvirt"
export CEPH_POOL="infra-pool"
export CEPH_RADOS_HOST="localhost"
export CEPH_RADOS_PORT="6789"
export VIRT_SCRT_UUID="$(uuidgen)"
export VIRT_SCRT_PATH="/tmp/libvirt-secret.xml"
export VIRT_POOL_PATH="/tmp/libvirt-rbd-pool.xml"
ceph osd pool create ${CEPH_POOL} ${CEPH_PGS} ${CEPH_PGS}
rbd pool init ${CEPH_POOL}
ceph auth get-or-create "client.${CEPH_USER}" mon "profile rbd" osd "profile rbd pool=${CEPH_POOL}"
cat > "${VIRT_SCRT_PATH}" <<EOF
<secret ephemeral='no' private='no'>
<uuid>${VIRT_SCRT_UUID}</uuid>
<usage type='ceph'>
<name>client.${CEPH_USER} secret</name>
</usage>
</secret>
EOF
virsh secret-define --file "${VIRT_SCRT_PATH}"
virsh secret-set-value --secret "${VIRT_SCRT_UUID}" --base64 "$(ceph auth get-key client.${CEPH_USER})"
cat > "${VIRT_POOL_PATH}" <<EOF
<pool type="rbd">
<name>${CEPH_POOL}</name>
<source>
<name>${CEPH_POOL}</name>
<host name='hcn01' port='6789' />
<host name='hcn02' port='6789' />
<host name='hcn03' port='6789' />
<auth username='${CEPH_USER}' type='ceph'>
<secret uuid='${VIRT_SCRT_UUID}'/>
</auth>
</source>
</pool>
EOF
virsh pool-define "${VIRT_POOL_PATH}"
virsh pool-autostart "${CEPH_POOL}"
virsh pool-start "${CEPH_POOL}"
Copy the secret and the pool definition to the other hosts:
scp /tmp/libvirt-secret.xml hcn02:/root/
scp /tmp/libvirt-rbd-pool.xml hcn02:/root/
scp /tmp/libvirt-secret.xml hcn03:/root/
scp /tmp/libvirt-rbd-pool.xml hcn03:/root/
Configure the secret and the pool on the other hosts: (Get the UUID from the secret file)
virsh secret-define --file libvirt-secret.xml
virsh secret-set-value --secret "0ea17f3f-42b6-424b-a9cc-fed685e607db" --base64 "$(ceph auth get-key client.libvirt)"
virsh pool-define "libvirt-rbd-pool.xml"
virsh pool-autostart "infra-pool"
virsh pool-start "infra-pool"
OpenStack Controller VM
VM Creation
In this stage we will create a VM to run the OpenStack control plane. This is a chicken/egg situation. We’re building OpenStack to run our VMs but we need a VM to run OpenStack, therefore this VM lives outside of OpenStack.
Create a volume (Ceph block image):
virsh vol-create-as "infra-pool" "hcc01" --capacity "120G" --format raw
If you need to delete a volume for some reason:
virsh vol-delete --pool infra-pool --vol hcc01
Download the ubuntu 22.04 iso image. I moved the image to /tmp because libvirt has some default apparmor that stops it reading the home dir?
wget https://mirror.fsmg.org.nz/ubuntu-releases/22.04/ubuntu-22.04.3-live-server-amd64.iso
mv ubuntu-22.04.3-live-server-amd64.iso /tmp/
Create the VM. This will start the install from ISO and will connect the VM to the cl-mgmt vlan on br-infra bridge
virt-install \
--connect qemu:///system \
--virt-type kvm \
--name "hcc01" \
--vcpus="2" --memory "4096" \
--disk "vol=infra-pool/hcc01" \
--boot uefi \
--noautoconsole \
--cdrom "/tmp/ubuntu-22.04.3-live-server-amd64.iso" \
--os-variant "ubuntu22.04" \
--graphics vnc,listen=0.0.0.0 \
--network=bridge:br-infra,model=virtio,virtualport_type=openvswitch,target.dev=hcc01-clmgmt \
--xml './devices/interface[1]/vlan/tag/@id=2010' \
--autostart
Connect to VM with VNC and complete Ubuntu install.
virsh vncdisplay hcc01
Controller OS Build
- Set static ip on cl-mgmt network: 10.20.10.10/24
- Set gateway to main firewall 10.20.10.254
- Set DNS to 10.20.10.11,10.20.10.1210.20.10.13
- Seach domains i.rhysmg.nz
Note: When the VM first reboots after install it might shutdown, start it up again with:
virsh list --all
virsh start hcc01
- Set /etc/hosts file as per other nodes above
- Add the shared root public key to authorized keys
- Copy the root .ssh directory to hcc01 from another host. (NOTE: the Ceph public key can be removed from authorized_keys on hcc01)
- Test passwordless root to and from all hosts
- apt update / upgrade
- install chrony and point to hcn01 (IP address) as above
Ceph Setup for Controller
This lets us manage Ceph from the controller node and is also required for OpenStack Glance and Cinder to access Ceph
On the controller generate a minimal Ceph config, copy the admin keyring and install ceph packages.
mkdir /etc/ceph/
ssh hcn01 "ceph config generate-minimal-conf" | sudo tee /etc/ceph/ceph.conf
ssh hcn01 "ceph auth get-or-create client.admin" | sudo tee /etc/ceph/ceph.client.admin.keyring
chmod 660 /etc/ceph/ceph.client.admin.keyring
apt install ceph-common python3-rbd python3-rados
Run ceph health to make sure you can access the cluster.
Test live migration
Make sure you can live migrate the controller VM from host to host
virsh list --all
virsh migrate hcc01 --live qemu+ssh://hcn02/system
virsh list --all
Then from hcn02 MIGRATE IT BACK AGAIN! (see warning below)
virsh list --all
virsh migrate hcc01 --live qemu+ssh://hcn01/system
virsh list --all
==========WARNING==========
When we built the VM we set it to auto-start. If you migrate it to hcn02 and leave it running there then reboot hcn01, hcn01 will auto-start that VM. It doesn’t know that hcn02 is already running it. I will be writing to the same Ceph image as hcn02, there is no built-in mechanisms to prevent this. No, running the same VM from two different hosts will NOT provide high availability 😂! It will however kuzer your image. Ask me how I know. Libvirt expects that this kind of safety is handled by an orchestrator. E.g. OpenStack.
I think it’s probably better to use the following, so that the VM is only persisted on one host at a time, but I haven’t tried this yet:
virsh migrate hcc01 --live --persistent --undefinesource qemu+ssh://hcn03/system
===========================
OpenStack
Now we get into the meat of it - the OpenStack install. This has been cobbled together from various OpenStack and Ceph guides.
Create a DNS A record pointing to the controller VM. This just de-couples the OpenStack endpoints from the server name in case we want to swap out the controller VM one day or implement a load balancer
osc.i.rhysmg.nz. IN A 10.20.10.10
Add OpenStack Repo [All Nodes]
Add OpenStack repo for Ubuntu 22.04 and install the OpenStack client
add-apt-repository cloud-archive:antelope
apt install python3-openstackclient
Install Pre-req components on controller node
Install and configure MariaDB
apt install mariadb-server python3-pymysql
Edit /etc/mysql/mariadb.conf.d/99-openstack.cnf
[mysqld]
bind-address = 10.20.10.10
default-storage-engine = innodb
innodb_file_per_table = on
max_connections = 4096
collation-server = utf8_general_ci
character-set-server = utf8
Run secure install script (all default)
mysql_secure_installation
Install Rabbit Message Queue Service
apt install rabbitmq-server
rabbitmqctl add_user openstack RABBIT_PASS
rabbitmqctl set_permissions openstack ".*" ".*" ".*"
Install Memcached
apt install memcached python3-memcache
Edit /etc/memcached.conf and set the -l option with: -l 10.10.20.10 to make memcahced listen on cl-mgmt interface
I understand there is some work to properly secure memcached. I might come back to that at some point.
systemctl restart memcached
Install Etcd
apt install etcd
Edit /etc/default/etcd
ETCD_NAME="osc"
ETCD_DATA_DIR="/var/lib/etcd"
ETCD_INITIAL_CLUSTER_STATE="new"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster-01"
ETCD_INITIAL_CLUSTER="osc=http://osc.i.rhysmg.nz:2380"
ETCD_INITIAL_ADVERTISE_PEER_URLS="http://osc.i.rhysmg.nz:2380"
ETCD_ADVERTISE_CLIENT_URLS="http://osc.i.rhysmg.nz:2379"
ETCD_LISTEN_PEER_URLS="http://10.20.10.10:2380"
ETCD_LISTEN_CLIENT_URLS="http://10.20.10.10:2379"
systemctl enable etcd
systemctl restart etcd
OpenStack Services
Now we start with the OpenStack components.
Install Keystone (Controller)
https://docs.openstack.org/keystone/latest/install/keystone-install-ubuntu.html
mysql
CREATE DATABASE keystone;
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' IDENTIFIED BY 'KEYSTONE_DBPASS';
GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' IDENTIFIED BY 'KEYSTONE_DBPASS';
apt install keystone
Edit /etc/keystone/keystone.conf:
[database]
connection = mysql+pymysql://keystone:KEYSTONE_DBPASS@osc.i.rhysmg.nz/keystone
[token]
provider = fernet
su -s /bin/sh -c "keystone-manage db_sync" keystone
keystone-manage fernet_setup --keystone-user keystone --keystone-group keystone
keystone-manage credential_setup --keystone-user keystone --keystone-group keystone
keystone-manage bootstrap --bootstrap-password ADMIN_PWD \
--bootstrap-admin-url http://osc.i.rhysmg.nz:5000/v3/ \
--bootstrap-internal-url http://osc.i.rhysmg.nz:5000/v3/ \
--bootstrap-public-url http://osc.i.rhysmg.nz:5000/v3/ \
--bootstrap-region-id Auckland
Edit /etc/apache2/apache2.conf:
ServerName osc.i.rhysmg.nz
service apache2 restart
At this point create an rc file so we can authenticate with keystone:
create admin-openrc:
export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_NAME=admin
export OS_USERNAME=admin
export OS_PASSWORD=ADMIN_PASS
export OS_AUTH_URL=http://osc.i.rhysmg.nz:5000/v3
export OS_IDENTITY_API_VERSION=3
export OS_IMAGE_API_VERSION=2
Source this openrc script:
source admin-openrc
Create initial OpenStack objects
Create a project (tenant) for services
openstack project create --domain default --description "Service Project" service
Here you can create yourself and user and a playpen project.
openstack project create --domain default --description "Fairburn Project" fairburn
openstack user create --domain default --password-prompt rhys
openstack role add --project fairburn --user rhys admin
Create a service role. This is all about this: https://docs.openstack.org/cinder/latest/configuration/block-storage/service-token.html Before doing this, volume detach was failing. We’ll add this role to the cinder and nova openstack identities later
openstack role create service
Install Glance (Controller)
mysql
CREATE DATABASE glance;
GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'localhost' IDENTIFIED BY 'GLANCE_DBPASS';
GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'%' IDENTIFIED BY 'GLANCE_DBPASS';
openstack user create --domain default --password-prompt glance
openstack role add --project service --user glance admin
openstack service create --name glance --description "OpenStack Image" image
openstack endpoint create --region Auckland image public http://osc.i.rhysmg.nz:9292
openstack endpoint create --region Auckland image internal http://osc.i.rhysmg.nz:9292
openstack endpoint create --region Auckland image admin http://osc.i.rhysmg.nz:9292
apt install glance
Ceph setup for Glance
Create a Ceph pool and user for glance
ceph osd pool create images
rbd pool init images
ceph auth get-or-create client.glance mon 'profile rbd' osd 'profile rbd pool=images' mgr 'profile rbd pool=images'
ceph auth get-or-create client.glance | tee /etc/ceph/ceph.client.glance.keyring
chown glance:glance /etc/ceph/ceph.client.glance.keyring
chmod 660 /etc/ceph/ceph.client.glance.keyring
Resume Glance setup
edit /etc/glance/glance-api.conf:
[DEFAULT]
show_image_direct_url = True
[database]
connection = mysql+pymysql://glance:GLANCE_DBPASS@osc.i.rhysmg.nz/glance
[glance_store]
stores = rbd
default_store = rbd
rbd_store_pool = images
rbd_store_user = glance
rbd_store_ceph_conf = /etc/ceph/ceph.conf
rbd_store_chunk_size = 8
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000
auth_url = http://osc.i.rhysmg.nz:5000
memcached_servers = osc.i.rhysmg.nz:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = glance
password =
[paste_deploy]
flavor = keystone
#[oslo_limit]
#auth_url = http://osc.i.rhysmg.nz:5000
#auth_type = password
#user_domain_id = default
#username = MY_SERVICE
#system_scope = all
#password = MY_PASSWORD
#endpoint_id = ENDPOINT_ID
#region_name = RegionOne
I did not complete the [oslo_limit] config (commeted out above) as I think this is related to quotas which I’m not interested in at the moment
su -s /bin/sh -c "glance-manage db_sync" glance
systemctl restart glance-api
Placement Service (Controller)
mysql
CREATE DATABASE placement;
GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'localhost' IDENTIFIED BY 'PLACEMENT_DBPASS';
GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'%' IDENTIFIED BY 'PLACEMENT_DBPASS';
openstack user create --domain default --password-prompt placement
openstack role add --project service --user placement admin
openstack service create --name placement --description "Placement API" placement
openstack endpoint create --region Auckland placement public http://osc.i.rhysmg.nz:8778
openstack endpoint create --region Auckland placement internal http://osc.i.rhysmg.nz:8778
openstack endpoint create --region Auckland placement admin http://osc.i.rhysmg.nz:8778
edit /etc/placement/placement.conf:
[api]
auth_strategy = keystone
[keystone_authtoken]
auth_url = http://osc.i.rhysmg.nz:5000/v3
memcached_servers = osc:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = placement
password = PLACEMENT_PASS
[placement_database]
connection = mysql+pymysql://placement:PLACEMENT_DBPASS@osc.i.rhysmg.nz/placement
apt install placement-api
su -s /bin/sh -c "placement-manage db sync" placement
systemctl restart apache2
Install Nova API (Controller)
https://docs.openstack.org/nova/latest/install/controller-install-ubuntu.html
mysql
CREATE DATABASE nova_api;
CREATE DATABASE nova;
CREATE DATABASE nova_cell0;
GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS';
GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS';
GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS';
GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' IDENTIFIED BY 'NOVA_DBPASS';
GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' IDENTIFIED BY 'NOVA_DBPASS';
openstack user create --domain default --password-prompt nova
openstack role add --project service --user nova admin
openstack role add --user nova --project service service
openstack service create --name nova --description "OpenStack Compute" compute
openstack endpoint create --region Auckland compute public http://osc.i.rhysmg.nz:8774/v2.1
openstack endpoint create --region Auckland compute internal http://osc.i.rhysmg.nz:8774/v2.1
openstack endpoint create --region Auckland compute admin http://osc.i.rhysmg.nz:8774/v2.1
apt install nova-api nova-conductor nova-novncproxy nova-scheduler
Edit /etc/nova/nova.conf:
[DEFAULT]
lock_path = /var/lock/nova
state_path = /var/lib/nova
transport_url = rabbit://openstack:RABBIT_PASS@osc.i.rhysmg.nz:5672/
my_ip = 10.0.0.11
[api]
auth_strategy = keystone
[api_database]
connection = mysql+pymysql://nova:NOVA_DBPASS@osc.i.rhysmg.nz/nova_api
[database]
connection = mysql+pymysql://nova:NOVA_DBPASS@osc.i.rhysmg.nz/nova
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000/
auth_url = http://osc.i.rhysmg.nz:5000/
memcached_servers = osc:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = nova
password = NOVA_PASS
[oslo_concurrency]
lock_path = /var/lib/nova/tmp
[placement]
region_name = Auckland
project_domain_name = Default
project_name = service
auth_type = password
user_domain_name = Default
auth_url = http://osc.i.rhysmg.nz:5000/v3
username = placement
password = PLACEMENT_PASS
[service_user]
send_service_user_token = true
auth_url = http://osc.i.rhysmg.nz:5000/identity
auth_strategy = keystone
auth_type = password
project_domain_name = Default
project_name = service
user_domain_name = Default
username = nova
password = NOVA_PASS
[vnc]
enabled = true
server_listen = $my_ip
server_proxyclient_address = $my_ip
[scheduler]
discover_hosts_in_cells_interval = 300
Due to a packaging bug, remove the log_dir option from the [DEFAULT] section.
su -s /bin/sh -c "nova-manage api_db sync" nova
su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova
su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova
su -s /bin/sh -c "nova-manage db sync" nova
systemctl restart nova-api
systemctl restart nova-scheduler
systemctl restart nova-conductor
systemctl restart nova-novncproxy
Nova Compute Setup (All three compute nodes)
https://docs.openstack.org/nova/latest/install/compute-install-ubuntu.html https://docs.openstack.org/nova/latest/configuration/config.html
apt install nova-compute libvirt-clients -y
Edit /etc/nova/nova.conf: The only thing that needs to be chanaged for each node is the IP address in $my_ip
[DEFAULT]
lock_path = /var/lock/nova
state_path = /var/lib/nova
transport_url = rabbit://openstack:RABBIT_PASS@osc.i.rhysmg.nz
my_ip = 10.20.10.11
[api]
auth_strategy = keystone
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000/
auth_url = http://osc.i.rhysmg.nz:5000/
memcached_servers = osc:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = nova
password = NOVA_PASS
[libvirt]
cpu_mode = host-passthrough
rbd_user = cinder
rbd_secret_uuid = <update later>
images_type = rbd
images_rbd_pool = vms
images_rbd_ceph_conf = /etc/ceph/ceph.conf
disk_cachemodes="network=writeback"
hw_disk_discard = unmap
live_migration_scheme = ssh
[oslo_concurrency]
lock_path = /var/lib/nova/tmp
[placement]
region_name = Auckland
project_domain_name = Default
project_name = service
auth_type = password
user_domain_name = Default
auth_url = http://osc.i.rhysmg.nz:5000/v3
username = placement
password = PLACEMENT_PASS
[service_user]
send_service_user_token = true
auth_url = http://osc.i.rhysmg.nz/identity
auth_strategy = keystone
auth_type = password
project_domain_name = Default
project_name = service
user_domain_name = Default
username = nova
password = NOVA_PASS
[vnc]
enabled = true
server_listen = 0.0.0.0
server_proxyclient_address = $my_ip
novncproxy_base_url = http://osc.i.rhysmg.nz:6080/vnc_auto.html
[workarounds]
skip_cpu_compare_on_dest = true
Note, workaround for live migration above may be solved in a latter version. But I know my CPUs are identical.
Restart nova on the compute node systemctl restart nova-compute
Finally, On the controller add the compute nodes to Opentack and ensure they are all up:
su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
openstack compute service list
Configure passwordless ssh must be configured for the nova user: On each host: ‘usermod -s /bin/bash nova’
On hcn01:
su - nova
ssh-keygen -t ed25519 -C
edit /var/lib/nova/.ssh/authorized_keys and add the public key
echo 'StrictHostKeyChecking no' >> /var/lib/nova/.ssh/config
Now exit to root and copy the .ssh dir to the other hosts
scp -r /var/lib/nova/.ssh remote-host:/var/lib/nova/
Make sure the /var/lib/nova/.ssh and it’s contents are owned by nova:nova on all hosts. Test with su - nova on each host and ensure passwordless ssh to and from all hosts as the nova user.
Neutron Setup on Controller
https://docs.openstack.org/neutron/latest/install/install-ubuntu.html https://docs.openstack.org/neutron/latest/configuration/config.html
mysql
CREATE DATABASE neutron;
GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'localhost' IDENTIFIED BY 'NEUTRON_DBPASS';
GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'%' IDENTIFIED BY 'NEUTRON_DBPASS';
openstack user create --domain default --password-prompt neutron
openstack role add --project service --user neutron admin
openstack role add --user cinder --project service service
openstack service create --name neutron --description "OpenStack Networking" network
openstack endpoint create --region Auckland network public http://osc.i.rhysmg.nz:9696
openstack endpoint create --region Auckland network internal http://osc.i.rhysmg.nz:9696
openstack endpoint create --region Auckland network admin http://osc.i.rhysmg.nz:9696
apt install neutron-server neutron-plugin-ml2
Edit /etc/neutron/neutron.conf:
[DEFAULT]
core_plugin = ml2
transport_url = rabbit://openstack:RABBIT_PASS@osc.i.rhysmg.nz
auth_strategy = keystone
notify_nova_on_port_status_changes = true
notify_nova_on_port_data_changes = true
dhcp_agents_per_network = 3
l3_ha = True
[database]
connection = mysql+pymysql://neutron:NEUTRON_DBPASS@osc.i.rhysmg.nz/neutron
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000
auth_url = http://osc.i.rhysmg.nz:5000
memcached_servers = osc:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = neutron
password = NEUTRON_PASS
[nova]
auth_url = http://osc.i.rhysmg.nz:5000
auth_type = password
project_domain_name = Default
user_domain_name = Default
region_name = Auckland
project_name = service
username = nova
password = NOVA_PASS
[oslo_concurrency]
lock_path = /var/lib/neutron/tmp
Edit /etc/neutron/plugins/ml2/ml2_conf.ini:
[ml2]
type_drivers = vlan,vxlan
tenant_network_types = vxlan
mechanism_drivers = openvswitch,l2population
extension_drivers = port_security
[ml2_type_vlan]
network_vlan_ranges = infra
[ml2_type_vxlan]
vni_ranges = 1:1000
Edit Nova config (On the controller still) /etc/nova/nova.conf:
[neutron]
auth_url = http://osc.i.rhysmg.nz:5000
auth_type = password
project_domain_name = Default
user_domain_name = Default
region_name = Auckland
project_name = service
username = neutron
password = NEUTRON_PASS
service_metadata_proxy = true
metadata_proxy_shared_secret = METADATA_SECRET
su -s /bin/sh -c "neutron-db-manage --config-file /etc/neutron/neutron.conf \
--config-file /etc/neutron/plugins/ml2/ml2_conf.ini upgrade head" neutron
systemctl restart nova-api
systemctl restart neutron-server
Neutron Setup on the network nodes
(Also the compute nodes in our case) We install the agents on all the compute nodes as we don’t have a dedicated network node, nor do we want network traffic to be handled by the controller node
apt install neutron-openvswitch-agent neutron-l3-agent neutron-dhcp-agent neutron-metadata-agent
Edit /etc/neutron/neutron.conf:
[DEFAULT]
core_plugin = ml2
transport_url = rabbit://openstack:RABBIT_PASS@osc.i.rhysmg.nz
auth_strategy = keystone
service_plugins = router
dns_domain = i.rhysmg.nz
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000
auth_url = http://osc.i.rhysmg.nz:5000
memcached_servers = osc:11211
auth_type = password
project_domain_name = Default
user_domain_name = Default
project_name = service
username = neutron
password = NEUTRON_PASS
[oslo_concurrency]
lock_path = /var/lib/neutron/tmp
Edit /etc/neutron/plugins/ml2/openvswitch_agent.ini:
The only thing that needs to be changed for each node is the local_ip
Note the bridge_mappings = infra:br-infra setting. This is where we connect OpenStack to the main physical uplink bridge (br-infra) which we created earlier. OpenStack then creates its own Open vSwitch bridges as per the diagram above, it’s in these bridges where all the networking magic happens.
[ovs]
bridge_mappings = infra:br-infra
local_ip = 10.20.30.11
[agent]
l2_population = true
tunnel_types = vxlan
[securitygroup]
firewall_driver = openvswitch
enable_security_group = true
Edit /etc/nova/nova.conf:
[neutron]
auth_url = http://osc.i.rhysmg.nz:5000
auth_type = password
project_domain_name = Default
user_domain_name = Default
region_name = Auckland
project_name = service
username = neutron
password = NEUTRON_PASS
Edit /etc/neutron/l3_agent.ini:
[DEFAULT]
interface_driver = openvswitch
# For router HA
ha_vrrp_health_check_interval = 5
Edit /etc/neutron/dhcp_agent.ini:
[DEFAULT]
interface_driver = openvswitch
dhcp_driver = neutron.agent.linux.dhcp.Dnsmasq
enable_isolated_metadata = true
force_metadata = true
dnsmasq_dns_servers = 10.20.10.11,10.20.10.12,10.20.10.13
Edit /etc/neutron/metadata_agent.ini:
[DEFAULT]
nova_metadata_host = osc.i.rhysmg.nz
metadata_proxy_shared_secret = METADATA_SECRET
Restart neutron services on all three nodes
systemctl restart nova-compute
systemctl restart neutron-openvswitch-agent
systemctl restart neutron-dhcp-agent
systemctl restart neutron-metadata-agent
Cinder setup on the controller node
mysql
CREATE DATABASE cinder;
GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'localhost' IDENTIFIED BY 'CINDER_DBPASS';
GRANT ALL PRIVILEGES ON cinder.* TO 'cinder'@'%' IDENTIFIED BY 'CINDER_DBPASS';
openstack user create --domain default --password-prompt cinder
openstack role add --project service --user cinder admin
openstack role add --user cinder --project service service
openstack service create --name cinderv3 --description "OpenStack Block Storage" volumev3
openstack endpoint create --region Auckland volumev3 public http://osc.i.rhysmg.nz:8776/v3/%\(project_id\)s
openstack endpoint create --region Auckland volumev3 internal http://osc.i.rhysmg.nz:8776/v3/%\(project_id\)s
openstack endpoint create --region Auckland volumev3 admin http://osc.i.rhysmg.nz:8776/v3/%\(project_id\)s
apt install cinder-api cinder-scheduler cinder-volume
Now a side-step to set up Ceph pools and authentication for Cinder & Nova
ceph osd pool create volumes
ceph osd pool create vms
rbd pool init volumes
rbd pool init vms
On the controller create the user which will be used by cinder (This will be used later in the cinder section)
ceph auth get-or-create client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images' mgr 'profile rbd pool=volumes, profile rbd pool=vms'
ceph auth get-or-create client.cinder >/etc/ceph/ceph.client.cinder.keyring
chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
chmod 660 /etc/ceph/ceph.client.cinder.keyring
chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
Copy the Ceph cinder keyring to /etc/ceph on the compute nodes, set permissions, and set the owner to nova
ceph auth get-or-create client.cinder | ssh hcn01 tee /etc/ceph/ceph.client.cinder.keyring
ssh hcn01 chown nova:nova /etc/ceph/ceph.client.cinder.keyring
ssh hcn01 chmod 660 /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh hcn02 tee /etc/ceph/ceph.client.cinder.keyring
ssh hcn02 chown nova:nova /etc/ceph/ceph.client.cinder.keyring
ssh hcn02 chmod 660 /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder | ssh hcn03 tee /etc/ceph/ceph.client.cinder.keyring
ssh hcn03 chown nova:nova /etc/ceph/ceph.client.cinder.keyring
ssh hcn03 chmod 660 /etc/ceph/ceph.client.cinder.keyring
Edit and add the following to /etc/ceph/ceph.conf on all the compute nodes
[client]
rbd cache = true
rbd cache writethrough until flush = true
#admin socket = /var/run/ceph/guests/$cluster-$type.$id.$pid.$cctid.asok
log file = /var/log/qemu/qemu-guest-$pid.log
rbd concurrent management ops = 20
Note: I commented out the admin socket for now, it’s causing an issue and I don’t understand it yet
Create dirs on each compute nodes
mkdir -p /var/run/ceph/guests/ /var/log/qemu/
chown libvirt-qemu:libvirt-qemu /var/run/ceph/guests /var/log/qemu/
On hcn01 create a libvirt secrete XML for cinder.
Note, I’m using the Ceph cluster ID as the UUID, I think this is some kind of a default?
Create secret.cinder.xml:
<secret ephemeral='no' private='no'>
<uuid>fd93fc22-2e5e-11ee-9452-e78e34109b9c</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
virsh secret-define --file cinder.secret.xml
virsh secret-set-value --secret "327a788a-3daa-11ee-9092-0d04acbcec26" --base64 "$(ceph auth get-key client.cinder)"
Copy the secret file and repeat secret creation on the other two nodes
scp cinder.secret.xml hcn02:/root/rhys/
scp cinder.secret.xml hcn03:/root/rhys/
Update the UUID in nova.conf on the compute nodes and in cinder.conf on the controller. This might not be required since we used the cluster id as the secret uuid?
Restart nova on all nodes
systemctl restart nova-compute
Now back to configuring Cinder on the controller node
Edit /etc/cinder/cinder.conf:
[DEFAULT]
transport_url = rabbit://openstack:RABBIT_PASS@osc.i.rhysmg.nz
auth_strategy = keystone
my_ip = 10.20.10.10
[database]
connection = mysql+pymysql://cinder:CINDER_DBPASS@osc.i.rhysmg.nz/cinder
[keystone_authtoken]
www_authenticate_uri = http://osc.i.rhysmg.nz:5000
auth_url = http://osc.i.rhysmg.nz:5000
memcached_servers = osc:11211
auth_type = password
project_domain_name = default
user_domain_name = default
project_name = service
username = cinder
password = CINDER_PASS
[oslo_concurrency]
lock_path = /var/lib/cinder/tmp
su -s /bin/sh -c "cinder-manage db sync" cinder
Still on the controller edit /etc/nova/nova.conf:
[cinder]
os_region_name = Auckland
systemctl restart nova-api
systemctl restart apache2
systemctl restart cinder-volume
systemctl restart cinder-scheduler
Start using OpenStack
We’ve completed install of all the components. Now we need to start using OpenStack, including creating some base networks, images and test virtual machines. This will soon show up all the things we messed up along the way, at which point we need to dig into logs, retrace our steps, and make corrections. But first try a reboot of the controller and the compute nodes before doing too much digging.
Transit network (New Provider VLAN Network)
The first network we’ll create will be an external transit VLAN for routing self-service networks up to the main firewall. This firewall already has an interface on this VLAN and rules to allow internet access.
With the appropriate rules and routes on the firewall, this transit network also access into OpenStack self-service networks from the wider external networks.
Note how we connect this network to the physical provider network infra which is mapped to the br-infra Open vSwitch bridge in the file /etc/neutron/plugins/ml2/openvswitch_agent.ini bridge_mappings = infra:br-infra
openstack network create --share --provider-physical-network infra --provider-network-type vlan --provider-segment 2501 --external ExtTransit
openstack subnet create --subnet-range 10.25.1.0/24 --gateway 10.25.1.254 --network ExtTransit --no-dhcp ExtTransit
Now we’ll create a router with has an interface in the external transit network we just created. Note: I’ve specified –disable-snat this is because I want all NAT work to be handled by my core firewall. Your situation might be different.
openstack router create CoreRouter
openstack router set CoreRouter --external-gateway ExtTransit --disable-snat --fixed-ip subnet=ExtTransit,ip-address=10.25.1.1
cl-mgmt network
Next we’ll create a network attached to the cl-mgmt vlan so we can place our OpenStack dashboard VM on this network along with the physical compute nodes and the controller VM.
openstack network create --share --provider-physical-network infra --provider-network-type vlan --provider-segment 2010 cl-mgmt
openstack subnet create --subnet-range 10.20.10.0/24 --gateway 10.20.10.254 --network cl-mgmt --no-dhcp cl-mgmt
First VXLAN Self-service Network
Now we switch users and projects and create a self-service (vxlan) network in the fairburn project.
Create a rhys-openrc script”
export OS_PROJECT_DOMAIN_NAME=Default
export OS_USER_DOMAIN_NAME=Default
export OS_PROJECT_NAME=fairburn
export OS_USERNAME=rhys
export OS_PASSWORD=[password]
export OS_AUTH_URL=http://osc.i.rhysmg.nz:5000/v3
export OS_IDENTITY_API_VERSION=3
export OS_IMAGE_API_VERSION=2
- Source the file:
source rhys-openrc
Create a self-service network, subnet, and router interface.
openstack network create fairburnlab
openstack subnet create --network fairburnlab --gateway 10.21.10.1 --subnet-range 10.21.10.0/24 fairburnlab
openstack router add subnet CoreRouter fairburnlab
Launch a test instance
Finally! We create a VM on our new infrastructure.
NOTE: Flavors should have cpu sockets set to max 1, otherwise performance is BAD (at least in Windows)
NOTE: We return the admin project/user for some of these steps then back to our own user again. I.e. the flavor and image are created in the admin project but the keypair and the instance will be created in the fairburn project.
. admin-openrc
openstack flavor create --vcpus 2 --ram 1024 --disk 30 --property hw:cpu_sockets=1 m1.small
openstack flavor create --vcpus 2 --ram 2024 --disk 60 --property hw:cpu_sockets=1 m1.medium
openstack flavor create --vcpus 2 --ram 4096 --disk 120 --property hw:cpu_sockets=1 m1.large
openstack flavor create --vcpus 4 --ram 8192 --disk 250 --property hw:cpu_sockets=1 m1.xl
. rhys-openrc
wget https://github.com/rhysmg.keys
openstack keypair create --public-key ./rhysmg.keys github_rhysmg
openstack security group list
openstack security group rule create --proto icmp UUID_OF_DEFAULT_SECURITY_GROUP_FOR_THIS_PROJECT
openstack security group rule create --proto tcp --dst-port 22 UUID_OF_DEFAULT_SECURITY_GROUP_FOR_THIS_PROJECT
. admin-openrc
wget https://cloud-images.ubuntu.com/jammy/current/jammy-server-cloudimg-amd64.img
qemu-img convert -f qcow2 -O raw jammy-server-cloudimg-amd64.img jammy-server-cloudimg-amd64.raw
openstack image create --disk-format raw --container-format bare --public --file ./jammy-server-cloudimg-amd64.raw ubuntu-server-22.04
openstack image list
openstack network list
openstack security group list
. rhys-openrc
openstack server create --flavor m1.small --image be5a0b72-a78b-4b77-acee-487ff40b830d \
--nic net-id=eab7dc39-5c2c-447d-b58f-0e86f599df9e --security-group 77cd0cc0-800d-4b2a-af31-5fba5b746186 \
--key-name github_rhysmg test01
openstack console url show test01
openstack server list
ssh 10.21.10.236
At this point you should be able SSH to the new VM.
If you are using an Ubuntu cloud image the default user is ‘ubuntu’ and there is no default password so you must SSH auth. If SSH auth doesn’t work it’s probably because the public key was not inserted correctly by cloud-init during the build, and this probably means there is a problem with the metadata service.
Note on DNS Forwarding
VMs in self-service networks point to the DHCP/DNS agent (dnsmasq) for their DNS service. Earlier we configured the DHCP agent to forward DNS queries to the bind9 DNS service running on our hosts, listening on the cl-mgmt network. The cl-mgmt network is not connected to the core router. Rather, its default gateway is the main firewall. The ExtTransit network has an interface on the CoreRouter and on the main firewall. So the DHCP agent will go up through the transit network through the main firewall to the DNS services on the cl-mgmt networks. This means the appropriate firewall rules must be configured to allow this. Likewise, the ACL in /etc/bind/named.conf.options on each node needs to be configured to accept queries from these networks. If you have SNAT enabled on your CoreRouter these queries will be sourced from the ExtTransit interface on the CoreRouter, if SNAT is disabled, it will be sourced from the DHCP aagent IP address for the given network. E.g. for the network 10.21.10.0/24 there are three DHCP agents running (one on each host) and their IPs are 10.21.10.2,3,4.
Next up, let’s test live migration. Check the current host of test01, do the live migration, check the host again:
openstack server show test01 |grep compute_host
openstack server migrate --live-migration test01
openstack server show test01 |grep compute_host
If this fails, and if /var/log/nova/nova-compute.log on the source host shows a Live Migration failure: Cannot recv data: Host key verification failed error this could be because the host key is not in the known_hosts file in the .ssd directory for root. Or it at least not recorded against the correct host name. For example, you might ssh hcn01.i.rhysmg.nz or ssh 10.20.10.11 and accept the key, getting it saved to known_hosts file. But libvirt uses the bare host name, not the FQDN, and not the IP address, so you need to ssh hcn01 and accept the key. Do this to and from all compute nodes. Strict host checking could be disabled but that’s not good practice, especially bad for the root user.
Note that we also configured passwordless ssh for the nova user earlier. I’m not 100% clear on this yet but in some cases the nova user is performing SSH interactions between nodes, other times it’s the root user so both scenarios need to be configured and working.
Create a dashboard VM
Now we’ll create a VM on the cl-mgmt network for an OpenStack web GUI, in this case Skyline. Everyone? likes a nice shiny gui but really in the OpenStack world it’s a nice-to-have and not a substitute for the CLI. Hence, unlike the controller we don’t mind running this one within OpenStack itself, since if it’s unavailable, it’s not a big deal.
VM Build
Below I first create a self-service network in the admin tenant. I’ll build the new dashboard VM on this network before moving it on the cl-mgmt network because cl-mgmt doens’t have DHCP or access to the metadata service. This is a clunky way to do it, i’ll refine this later.
Also add rules to allow SSH and ICMP via the default security group (in the admin project). Earlier we did this for the fairburn project.
. admin-openrc
openstack network create admin_build
openstack subnet create --network admin_build --gateway 10.21.99.1 --subnet-range 10.21.99.0/24 admin_build
openstack router add subnet CoreRouter admin_build
openstack security group rule create --proto icmp 08bf355a-d1f1-404a-8c78-41cfe6160c6a
openstack security group rule create --proto tcp --dst-port 22 08bf355a-d1f1-404a-8c78-41cfe6160c6a
openstack flavor list
openstack image list
openstack network list
openstack security group list
openstack server create --flavor m1.medium --image ubuntu-server-22.04 --nic net-id=2af5135a-a5d0-40e7-b170-22ccb61465e8 --security-group 08bf355a-d1f1-404a-8c78-41cfe6160c6a --key-name github_rhysmg hcui01
openstack server list
Once the VM is running and we can connect to it on it’s self-service IP, we’ll add another network interface on the cl-mgmt network.
openstack port create --network 9bc46380-07be-4045-94ea-1c73c1db019d --disable-port-security --fixed-ip subnet=cl-mgmt,ip-address=10.20.10.5 port_hcui01
openstack server add port hcui01 port_hcui01
Now running ip link within the hcui01 VM should show an additional interface which can be configured with netplan with a static address. E.g.
network:
version: 2
ethernets:
ens3:
dhcp4: true
match:
macaddress: fa:16:3e:c8:b7:f7
set-name: ens3
ens7:
dhcp4: false
addresses: [10.20.10.5/24]
routes:
- to: default
via: 10.20.10.254
nameservers:
addresses:
- 10.20.10.13
- 10.20.10.11
- 10.20.10.12
match:
macaddress: fa:16:3e:88:63:d8
set-name: ens7
Once the new interface is up and accessible, we can remove the port for the build network:
openstack port list
openstack server remove port hcui01 83b91264-4865-4a6b-8146-184c3ce693b1
Then update the netplan again to remove that interface from the OS
Now we have our dashboard VM on the cl-mgmt network it’s ready to configure.
Dashboard OS
Configure /etc/hosts with the FQDN:
127.0.0.1 localhost
10.20.10.5 hcui01.i.rhysmg.nz hcui01
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
ff02::3 ip6-allhosts
(Optional) configure passwordless ssh for root as we’ve done previously
Install chrony and point to hcn01 (IP Address) as above
apt update
apt upgrade
apt install chrony
Skyline Dashboard install
apt install mariadb-server
mysql_secure_installation
mysql
CREATE DATABASE skyline DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON skyline.* TO 'skyline'@'localhost' IDENTIFIED BY 'SKYLINE_DBPASS';
GRANT ALL PRIVILEGES ON skyline.* TO 'skyline'@'%' IDENTIFIED BY 'SKYLINE_DBPASS';
On the controller create an OpenStack user
openstack user create --domain default --password-prompt skyline
openstack role add --project service --user skyline admin
Resume on dashboard host
Install Docker:
apt install apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
apt update
apt-cache policy docker-ce
apt install docker-ce
systemctl restart docker
systemctl status docker
Skyline install and configure Skyline
- NOTE: If you are not using FQDNs then use the IP address in the keystone URL because it doesn’t like non-FQDNs for some reason??
docker pull 99cloud/skyline:latest
mkdir -p /etc/skyline /var/log/skyline /var/lib/skyline /var/log/nginx
Edit /etc/skyline/skyline.yaml:
default:
database_url: mysql://skyline:SKYLINE_DBPASS@localhost:3306/skyline
debug: true
log_dir: /var/log
openstack:
keystone_url: http://osc.i.rhysmg.nz:5000/v3/
system_user_password: SKYLINE_PASS
default_region: Auckland
chmod 660 /etc/skyline/skyline.yaml
Bootstrap Skyline
docker run --name skyline_bootstrap \
-e KOLLA_BOOTSTRAP="" \
-v /etc/skyline/skyline.yaml:/etc/skyline/skyline.yaml \
-v /var/log:/var/log \
--net=host 99cloud/skyline:latest
Clean up the bootstrap
docker rm -f skyline_bootstrap
NOTE: If you want to deploy TLS from the get-go skip to the TLS section below to start the skyline server with certificate specified. Start Skyline
docker run -d --name skyline --restart=always \
-v /etc/skyline/skyline.yaml:/etc/skyline/skyline.yaml \
-v /var/log:/var/log \
--net=host 99cloud/skyline:latest
Finally! A UI: http://hcui01.i.rhysmg.nz:9999/
But seriously, get familiar with the OpenStack CLI/API, the UI is just for fun.
Quotas
openstack quota show --all
TLSify
I wasn’t brave enough to do https throughout or certificate-based auth for keystone. I’d like to come back and do this at some point, maybe on the next build. But let’s at least add a let’s encrypt cert for the Ceph dashboard and Skyline. A separate process will need to be developed to update these every time the cert renews.
Certbot for wildcard with Cloudflare DNS (Do this on the controller)
Here we create a wild card certificate that can be used for web interfaces.
Create API token in cloudflare with DNS:Edit
mkdir -p /root/sec/certbot
Create /root/sec/certbot/cf with dns_cloudflare_api_token = my_cloudFlaretoken
chmod 660 -R /root/sec/
snap install --classic certbot
ln -s /snap/bin/certbot /usr/bin/certbot
snap set certbot trust-plugin-with-root=ok
snap install certbot-dns-cloudflare
certbot certonly --dns-cloudflare --dns-cloudflare-credentials /root/sec/certbot/cf -d *.i.rhysmg.nz --key-type rsa --rsa-key-size 2048
TLS for Ceph Dashboard
Do this on the controller
Note: Ceph dashboard supports RSA certs not ED25119, which is what we created above
ceph dashboard set-ssl-certificate -i /etc/letsencrypt/live/i.rhysmg.nz/cert.pem
ceph dashboard set-ssl-certificate-key -i /etc/letsencrypt/live/i.rhysmg.nz/privkey.pem
ceph mgr module disable dashboard
ceph mgr module enable dashboard
ceph health
Revert to self-signed if something goes wrong:
ceph config-key rm mgr/dashboard/key
ceph config-key rm mgr/dashboard/crt
ceph mgr module disable dashboard
ceph mgr module enable dashboard
ceph dashboard create-self-signed-cert
Enable redirect_resolve_ip_addr so that if the active manager moves to a different host, the FQDN, rather than the IP address will be used in the redirect. - Requires reverse DNS zone or host file on each Ceph node
ceph config set mgr mgr/dashboard/redirect_resolve_ip_addr True
Yet to try this.
ceph config-key set mgr/cephadm/{hostname}/grafana_key -i $PWD/key.pem ceph config-key set mgr/cephadm/{hostname}/grafana_crt -i $PWD/certificate.pem
TLS for Skyline Dashboard
Make a certs directory on huci01: /etc/skyline/certs/
From the controller copy the let’s encrypt certificates to huci01
scp -r /etc/letsencrypt/live/i.rhysmg.nz/ hcui01:/etc/skyline/certs/
On hcui01. Stop and remove the skyline docker image and run it again with the certificate specified. We’ll also set it to run of port 443.
docker ps --all
docker stop 6f3c7937455d bash
docker rm 6f3c7937455d bash
docker run -d --name skyline --restart=always -e SSL_CERTFILE=/etc/skyline/certs/i.rhysmg.nz/cert.pem -e SSL_KEYFILE=/etc/skyline/certs/i.rhysmg.nz/privkey.pem -e LISTEN_ADDRESS=0.0.0.0:443 -v /etc/skyline/certs/:/etc/skyline/certs/ -v /etc/skyline/skyline.yaml:/etc/skyline/skyline.yaml -v /var/log:/var/log --net=host 99cloud/skyline:latest
In theory refreshing the cert should just be a case of copying the cert files back to that same path which we could do with a certbot hook. Later.
Simple Self CA
Credit: https://arminreiter.com/2022/01/create-your-own-certificate-authority-ca-using-openssl/
CANAME=ca.i.rhysmg.nz
mkdir $CANAME
cd $CANAME
# generate aes encrypted private key
openssl genrsa -aes256 -out $CANAME.key 4096
# create certificate, 22 years
openssl req -x509 -new -nodes -key $CANAME.key -sha256 -days 8030 -out $CANAME.crt -subj '/CN=i.rhysmg.nz CA/C=NZ/ST=Auckland/L=Auckland/O=Fairburn'
#Add CA certs to Ubuntu trust store - I haven't done this.
sudo apt install -y ca-certificates
sudo cp $CANAME.crt /usr/local/share/ca-certificates
sudo update-ca-certificates
# Create wildcard cert
MYCERT=wild.i.rhysmg.nz
openssl req -new -nodes -out $MYCERT.csr -newkey rsa:4096 -keyout $MYCERT.key -subj '/CN=wild/C=NZ/ST=Auckland/L=Auckland/O=Fairburn'
# create a v3 ext file for SAN properties
cat > $MYCERT.v3.ext << EOF
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
subjectAltName = @alt_names
[alt_names]
DNS.1 = *.i.rhysmg.nz
DNS.2 = i.rhysmg.nz
EOF
#Sign the wildcard cert with the CA cert
openssl x509 -req -in $MYCERT.csr -CA $CANAME.crt -CAkey $CANAME.key -CAcreateserial -out $MYCERT.crt -days 4015 -sha256 -extfile $MYCERT.v3.ext
Snippets & Leftovers
The remainder of this post is just a scratchpad of snippets, notes and experiments. Much of it is likely incorrect or missing but there might be some gems amongst the trash.
Links to re-visit:
https://xahteiwi.eu/resources/hints-and-kinks/dos-donts-ceph-openstack/ http://www.yangguanjun.com/2015/11/17/cinder-with-multi-ceph-pools/ https://www.redhat.com/en/blog/9-tips-properly-configure-your-openstack-instance
Misc Tidy Up Tasks
- Check Perms/ownership of ceph keyrings
- Disable auto updates on all critical hosts (nodes + controller)
Edit: /etc/apt/apt.conf.d/20auto-upgrades:
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
Image Work
Properties for Windows images
These the properties which should be applied to a Windows image for secure boot and optimal? performance.
NOTE: The --property os_type=windows below is very important for Windows performance. As is setting sockets=1 on the flavour (or the image). See: https://www.safespring.com/blogg/2022/2022-02-windows-vm-cpu-perf/
--property os_distro=windows --property os_type=windows --property os_version=10 --property hw_scsi_model=virtio-scsi --property hw_disk_bus=scsi --property hw_qemu_guest_agent=yes --property os_require_quiesce=yes --property hw_machine_type=q35 --property hw_firmware_type=uefi --property os_secure_boot=required --property hw_vif_multiqueue_enabled=true
Interesting Image properties for Linux VMS
--property os_distro=ubuntu --property os_type=linux --property hw_vif_model=virtio --property hw_vif_multiqueue_enabled=true
Migrate Windows Hyper-V VM to OpenStack
There is a bunch of ways that you can approach this. This is the process I landed on after lot of trial and error.
Prepare the source VHDX (Clean up the disk/os as much as possible and shrink the partition) in disk manger. I leave ~2GB of free space so the OS can keep working. You might want to temporarily disable the page file while you do this, to maximize the shrink
Resize the VHDX with PowerShell resize-vhd or Hyper-V Manager
Copy the VHDX to one of the nodes (I’m using a secondary SSD in one of the nodes which I can thrash)
Convert the VHDX to raw with qemu-img:
qemu-img convert -f vhdx -O raw exc10.lab.rhysgoodwin.com.vhdx exc10.lab.rhysgoodwin.com.raw
Launch a VM with the raw image file using virt-install. Note that we need to boot from a windows ISO and enter repair mode to install the virtio storage driver. Note the VNC display number (97 below), you need to be ready with your VNC client to jump straight into the console and press any key to boot from CDROM. If you miss it, you might need to destroy the VM (virsh destroy exc10), undefine it (virsh undefine exc10 --nvram), and start again.
virt-install \
--boot firmware=efi,loader_secure=yes,menu=on \
--cdrom /imagework/win-2019/windows_server_2019_x64_dvd_f9475476.iso \
--features vmport.state=off,hyperv.vapic.state=on,hyperv.spinlocks.state=on,hyperv.spinlocks.retries=8191,hyperv.relaxed.state=on \
--clock offset=localtime,hypervclock_present=yes,rtc_tickpolicy=catchup,hpet_present=no,pit_tickpolicy=delay \
--machine q35 \
--vcpus sockets=1,cores=2 --cpu host-passthrough \
--graphics vnc,port=5997,listen=0.0.0.0 \
--sound ich9 \
--video qxl \
--memballoon virtio \
--name exc10 \
--os-variant win2k19 \
--network network=default,model=virtio \
--ram 4096 \
--controller=scsi,model=virtio-scsi \
--disk path=/imagework/exc10/exc10.lab.rhysgoodwin.com.raw,format=raw,device=disk,target.bus=virtio,driver.discard=unmap,cache=writeback,driver.io=threads \
--disk path=/imagework/virtio/virtio-win-0.1.229.iso,format=raw,device=cdrom,target.bus=sata,readonly=on
Once the Windows ISO boots, select language, then ‘repair your computer’, then troubleshoot, then command prompt
You can see the disks which are accessible using:
wmic logicaldisk get caption
One of the disks will be the virtio disk. Install the virtio storage drivers from amd64[os.ver]\ as follows:
E:\amd64\2k16\>drvload vioscsi.inf
E:\amd64\2k16\>drvload viostor.inf
Run: wmic logicaldisk get caption again and you should now see another drive letter, in my case C: this is the system disk of the source VM.
Use dism to insert the virtio storage drivers:
E:\amd64\2k16\>dism /image:D:\ /add-driver /driver: vioscsi.inf
E:\amd64\2k16\>dism /image:D:\ /add-driver /driver:\viostor.inf
Exit cmd and continue to boot. Windows should now boot and reconfigure itself for the new virtual hardware.
Log on to the VM and install the full virtio package from the attached disk.
Shutdown the VM and create an OpenStack image from the raw file
openstack image create --disk-format raw --container-format bare --public --file exc10.lab.rhysgoodwin.com.raw exc10
Set the properties of the image to suit Windows
openstack image set \
--property os_distro=windows \
--property os_type=windows \
--property os_version=2019 \
--property hw_scsi_model=virtio-scsi \
--property hw_disk_bus=scsi \
--property hw_qemu_guest_agent=yes \
--property os_require_quiesce=yes \
--property hw_machine_type=q35 \
--property hw_firmware_type=uefi \
--property os_secure_boot=required \
--property hw_vif_multiqueue_enabled=true exc10
Create the final VM from the image:
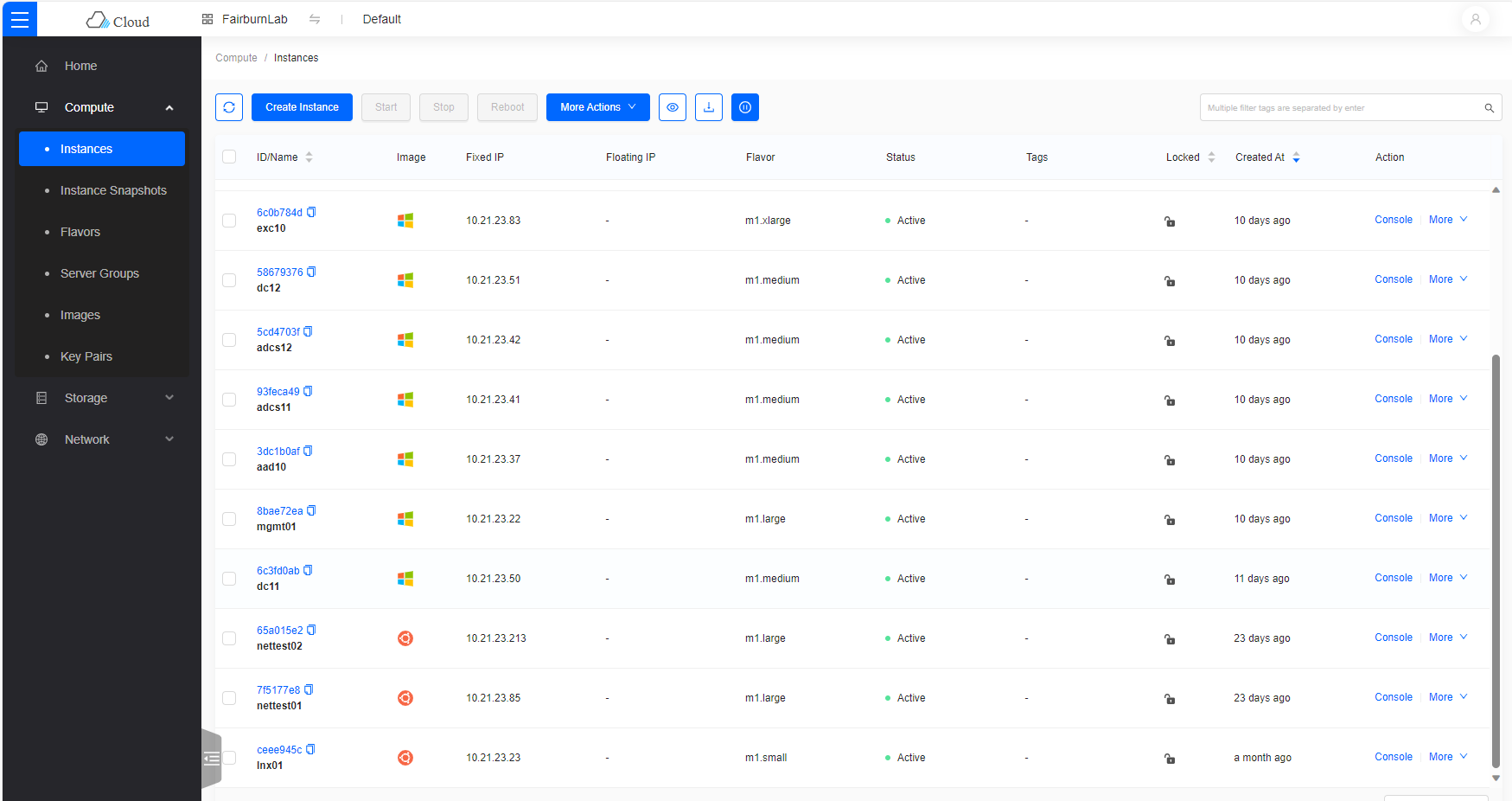
openstack server create --flavor m1.xlarge --image exc10 --nic net-id=fairburnlab,v4-fixed-ip=10.21.23.83 --security-group fairburn_lab exc10
Log onto the server and expand the disk.
To migrate secondary data disks, I used the following, it seems a bit hacky, is there a better way?:
As above, shrink the partition, shrink the VHDX, and convert to raw.
Create a new OpenStack volume the same size as the raw image:
openstack volume create --size 468 fs10-data01
Copy the Ceph image from the Ceph dashboard e.g. volume-e59f564b-abaf-4b8f-95ae-851233ffcf2d then delete the Ceph image from the Ceph dashboard. Note, OpenStack still thinks the volume exists.
Import the raw image into Ceph with the same name using rbd:
rbd import data01.raw volumes/volume-e59f564b-abaf-4b8f-95ae-851233ffcf2d
Expand the volume as needed:
openstack volume set --size 600 e59f564b-abaf-4b8f-95ae-851233ffcf2d
Now attach the volume to the server:
openstack server add volume fs10 e59f564b-abaf-4b8f-95ae-851233ffcf2d
New Windows Image Build
For Windows 10. Server 2016, 2019 etc.
- On one of the hosts create a VM on a local disk using virt-install.
virt-install \ --boot firmware=efi,loader_secure=yes \ --cdrom /imagework/win-2022/windows_server_2022_x64_dvd_63dab61a.iso \ --features vmport.state=off,hyperv.vapic.state=on,hyperv.spinlocks.state=on,hyperv.spinlocks.retries=8191,hyperv.relaxed.state=on \ --clock offset=localtime,hypervclock_present=yes,rtc_tickpolicy=catchup,hpet_present=no,pit_tickpolicy=delay \ --machine q35 \ --vcpus sockets=1,cores=2 --cpu host-model \ --graphics vnc,port=5999,listen=0.0.0.0 \ --sound ich9 \ --video qxl \ --memballoon virtio \ --name win22-img \ --os-variant win10 \ --network network=default,model=virtio \ --ram 4096 \ --controller=scsi,model=virtio-scsi \ --disk path=/imagework/win-2022/windows-server-2022-2023-11-14.qcow2,size=35,device=disk,target.bus=virtio,driver.discard=unmap,cache=writeback,driver.io=threads \ --disk path=/imagework/virtio/virtio-win-0.1.229.iso,format=raw,device=cdrom,target.bus=sata,readonly=on - Connect to the VNC console (above I’m using display number 98) ‘exit’ the UEFI menu and select the DVD from the boot manger and start the Windows install.
- You will need to load the virtio SCSI driver from the attached virtio ISO.
- Complete the Windows install. For Windows 10 create the first user as ‘Admin’.
The VM might stop when it goes for it’s first reboot, restart it with
virsh start win10-img - Install the full virtio package
- Update Windows
- Set PowerShell policy to unrestricted
- Disable Sleep (makes the VM die, haven’t looked too far into it yet)
- Configure Windows firewall
- Enable remote desktop
- Install cloudbase-init:
- Untick metadata password
- Username: Admin (win10) or Administrator (Win Server)
- run as local system
- no sysprep
- Use disk part to delete the recovery part (win10, Server 2022)
- powercfg.exe /hibernate off
- Configure cloud-init (Allow reboots)
- Shrink the system partition, leave ~2GB
- Take note of the final size of the OS partition e.g. 18GB
- (Optional) Shutdown the VM and make a pre-sysprep copy of the qcow image file in case you want to make more changes, then start the VM again with
virsh start win10-imgRun:
sysprep.exe /generalize /oobe /shutdown /unattend:C:\progra~1\cloudb~1\cloudb~1\conf\Unattend.xml
Once the VM shuts down after sysprep:
- Shrink the qcow2 image to the size noted above plus a bit more to be safe.
- Convert the image to raw
- Create an OpenStack image
- Set the image properties
qemu-img resize --shrink -f qcow2 win10-img.qcow2 19G
qemu-img convert -f qcow2 -O raw win10-img.qcow2 win10-img.raw
openstack image create --disk-format raw --container-format bare --public --file win10-img.raw win10-2023-08-21
openstack image set --property os_distro=windows --property os_type=windows --property os_version=10 --property hw_scsi_model=virtio-scsi --property hw_disk_bus=scsi --property hw_qemu_guest_agent=yes --property os_require_quiesce=yes --property hw_machine_type=q35 --property hw_firmware_type=uefi --property os_secure_boot=required --property hw_vif_multiqueue_enabled=true
win10-2023-08-21
Temp attach an ISO to an existing VM for troubleshooting
- Migrate the VM to the host where the iso is
- Get the KVM instance name with
openstack server show - Attache the ISO
virsh attach-disk instance-0000008f /imagework/ubuntu-22.04.3-live-server-amd64.iso hdc --type cdrom --config - Edit the instnace and set boot to cdrom:
virsh edit instance-0000008fhvm - Shutdown the instance
virsh shutdown instance-0000008f - Start the instnace
virsh start instance-0000008f - Get the the VNC display and connect
virsh vncdisplay instance-0000008f
Sophos XG Firewall Build
I use a Sophos XG VM as my main firewall and I run it outside of OpenStack.
virsh vol-create-as "infra-pool" "fwxg01" --capacity "250G" --format raw
virt-install \
--connect qemu:///system \
--virt-type kvm \
--machine q35 \
--name "fwxg01" \
--vcpus sockets=1,cores=4 --cpu host-model --memory "6114" \
--disk "vol=infra-pool/fwxg01,device=disk,target.bus=virtio,driver.discard=unmap,cache=writeback" \
--noautoconsole \
--cdrom "/tmp/SW-19.5.1_MR-1-278.iso" \
--os-variant "linux2020" \
--graphics vnc,listen=0.0.0.0 \
--network=bridge:br-infra,model=virtio,virtualport_type=openvswitch,target.dev=fw-infra-mgmt \
--network=bridge:br-infra,model=virtio,virtualport_type=openvswitch,target.dev=fwxg01-wan,driver.name=vhost,driver.queues=4 \
--network=bridge:br-infra,model=virtio,virtualport_type=openvswitch,target.dev=fwxg01-trunk,driver.name=vhost,driver.queues=4 \
--xml './devices/interface[1]/vlan/tag/@id=2040' \
--xml './devices/interface[2]/vlan/tag/@id=10' \
--autostart
Customize a cloud image
Install the libguestfs-tools on the server whre you do your image work.
Mainly from: More detail here: https://gist.github.com/si458/98aa940837784e9ef9bff9e24a7a8bfd#file-virt-customize-ubuntu22
apt -y install libguestfs-tools
virt-customize -a jammy-server-cloudimg-amd64.img --install qemu-guest-agent
virt-customize -a jammy-server-cloudimg-amd64.img --timezone Pacific/Auckland
virt-customize -a jammy-server-cloudimg-amd64.img --run-command 'sed -i s/^PasswordAuthentication.*/PasswordAuthentication\ yes/ /etc/ssh/sshd_config'
virt-customize -a jammy-server-cloudimg-amd64.img --root-password password:MePasword
Disk Work
Expand disk (For libvirt infra VMs)
qemu-img info -f rbd
qemu-img resize "rbd:infra-pool/hcc01" +60G
Get the name of the disk
virsh domblklist hcc01
virsh blockresize --domain hcc01 --path vda --size 120G
Extend ubuntu lvm after resizing disk
fdisk -l
growpart /dev/vda 3
pvresize /dev/vda3
lvextend -l +100%FREE /dev/ubuntu-vg/ubuntu-lv
resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
Extend ubuntu encrypted lvm after resizing disk
Credit: How to resize a LUKS encrypted root partion
#Grow the part
growpart /dev/vda 3
# resize the LUKS parititon (dm_crypt-0)
cryptsetup resize dm_crypt-0
# resize the physical device on top of it
pvresize /dev/mapper/dm_crypt-0
# resize the logical device (ubuntu--vg-ubuntu--lv)
lvextend -l +100%FREE /dev/mapper/ubuntu--vg-ubuntu--lv
# grow the file system accordingly
resize2fs /dev/mapper/ubuntu--vg-ubuntu--lv
Remember to reset the LUKS password from the default image
cryptsetup luksAddKey /dev/vda3
# Reboot and test new key, then remove the old key
cryptsetup luksRemoveKey /dev/vda3
Useful Ceph Commands
Prep cluster for shutdown of one or all hosts
If shutting down all hosts obviously stop all work loads running on Ceph. In my case I’d connect directly to the infra-mgmt VLAN to do this because access to the cl-mgmt interfaces is via the firewall which is stored on the cluster. If shutting down one host then the cluster will stay up.
Check Health:
ceph status
ceph health
Disable recovery
ceph osd set noout
ceph osd set nobackfill
ceph osd set norecover
Resume normal operation
ceph osd unset norecover
ceph osd unset nobackfill
ceph osd unset noout
Crashes & Health
ceph health detail
ceph crash ls
ceph crash info 2023-08-15T08:50:29.609422Z_bbdd35e2-4567-47be-bc19-8a0686a1b886
ceph crash archive-all
If a host is marked as offline when really it isn’t:
ceph cephadm check-host hcn03
Adding a new set of disks
Here are steps I took to add a new 2TB sata disk to each host
- Create new sata0
- Create a new crush rule class and crush rule
- Create a new pools ‘volumes2’
- Assign the new crush rule to the new pool
- Update the capabilites for the client.cinder user
ceph osd crush rm-device-class osd.3
ceph osd crush rm-device-class osd.4
ceph osd crush rm-device-class osd.5
ceph osd crush set-device-class sata0 osd.3
ceph osd crush set-device-class sata0 osd.4
ceph osd crush set-device-class sata0 osd.5
ceph osd crush rule create-replicated replicated_rule_sata0 default host sata0
ceph osd pool create volumes2
rbd pool init volumes2
ceph osd pool set volumes2 crush_rule replicated_rule_sata0
ceph auth get client.cinder
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=volumes2, profile rbd pool=vms, profile rbd-read-only pool=images' mgr 'profile rbd pool=volumes, profile rbd pool=volumes2, profile rbd pool=vms'
ceph auth get client.cinder
Next add a new backend to Cinder Thanks to https://www.sebastien-han.fr/blog/2013/04/25/ceph-and-cinder-multi-backend/
Edit /etc/cinder/cinder.conf:
enabled_backends = ceph-nvme0,ceph-sata0
#....
[ceph-sata0]
volume_driver = cinder.volume.drivers.rbd.RBDDriver
volume_backend_name = ceph-sata0
rbd_pool = volumes2
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = false
rbd_max_clone_depth = 5
rbd_store_chunk_size = 4
rados_connect_timeout = -1
rbd_user = cinder
rbd_secret_uuid = 327a788a-3daa-11ee-9092-0d04acbcec26
cinder type-create nvme0
cinder type-key nvme0 set volume_backend_name=ceph-nvme0
cinder type-create sata0
cinder type-key sata0 set volume_backend_name=ceph-sata0
cinder extra-specs-list
systemctl restart cinder-scheduler.service
systemctl restart cinder-volume.service
Now you should be able to create volumes with the two types instead of the default type
Windows VM Crash issue
I’ve had a couple of Windows VMs crash. Testing this solution. https://bugs.launchpad.net/ubuntu/+source/linux/+bug/2015455
cat /sys/module/kvm/parameters/tdp_mmu
echo "options kvm tdp_mmu=N" >/etc/modprobe.d/kvm-disable-tdp-mmu.conf
cat /sys/module/kvm/parameters/tdp_mmu
Then reboot.
Monitoring server build
- Create server mon01 on home servers, ssh and set passwd for user ubuntu
- Add cl-mgm interface, remove home-servers interface
- Console to server and disable cloud init
touch /etc/cloud/cloud-init.disabled - Configure netplan
- Install chrony and point hcn01
- update
apt update
apt upgrade
Install grafana
Credit: https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-grafana-on-ubuntu-22-04
wget -q -O - https://packages.grafana.com/gpg.key | gpg --dearmor | sudo tee /usr/share/keyrings/grafana.gpg > /dev/null
echo "deb [signed-by=/usr/share/keyrings/grafana.gpg] https://packages.grafana.com/oss/deb stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
apt update
apt install grafana
Configure Grafana
[server]
protocol = https
http_port = 3000
domain = mon.i.rhysmg.nz
cert_file = /etc/grafana/certs/wild.i.rhysmg.nz.crt
cert_key = /etc/grafana/certs/wild.i.rhysmg.nz.key
Start and enable Grafana service
systemctl start grafana-server
systemctl status grafana-server
systemctl enable grafana-server
Install Prometheus Server
wget https://github.com/prometheus/prometheus/releases/download/v2.47.2/prometheus-2.47.2.linux-amd64.tar.gz
groupadd --system prometheus
useradd -s /sbin/nologin --system -g prometheus prometheus
mkdir /etc/prometheus
mkdir /var/lib/prometheus
tar vxf prometheus*.tar.gz
cd prometheus*/
mv prometheus /usr/local/bin
mv promtool /usr/local/bin
chown prometheus:prometheus /usr/local/bin/prometheus
chown prometheus:prometheus /usr/local/bin/promtool
mv consoles /etc/prometheus
mv console_libraries /etc/prometheus
mv prometheus.yml /etc/prometheus
chown prometheus:prometheus /etc/prometheus
chown -R prometheus:prometheus /etc/prometheus/consoles
chown -R prometheus:prometheus /etc/prometheus/console_libraries
chown -R prometheus:prometheus /var/lib/prometheus
Create service unit at /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
[Install]
WantedBy=multi-user.target
Enable and start service
systemctl daemon-reload
systemctl enable prometheus
systemctl start prometheus
Install Prometheus Node Exporter (On other hosts to be monitored)
wget https://github.com/prometheus/node_exporter/releases/download/v1.6.1/node_exporter-1.6.1.linux-amd64.tar.gz
tar vxf node_exporter*.tar.gz
cd node_exporter*/
mv node_exporter /usr/local/bin
groupadd --system node_exporter
useradd -s /sbin/nologin --system -g node_exporter node_exporter
Create service unit at /etc/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
Enable and start service
systemctl daemon-reload
systemctl enable node_exporter
systemctl start node_exporter
systemctl status node_exporter
Resource Allocation Issue
I was having issues with migrating VMs and was getting this notice in /var/log/nova/nova-scheduler.log
Got no allocation candidates from the Placement API. This could be due to insufficient resources or a temporary occurrence as compute nodes start up.
I found the VCPU ratio was set to 4. I have 8 cores so that only allowed up to 32 vCPUs to be allocated. This applies even if not all the VMs are powerd on. So I increased the ration to 16.
openstack resource provider list
openstack resource provider inventory list 27202a9f-e2ca-42d7-b147-f6cbb4397198
openstack resource provider inventory class set 27202a9f-e2ca-42d7-b147-f6cbb4397198 VCPU --total 8 --max_unit 8 --allocation_ratio 16
openstack resource provider inventory list 27202a9f-e2ca-42d7-b147-f6cbb4397198
Duplicate Port Binding
Credit: https://bugs.launchpad.net/neutron/+bug/1849802/comments/7
Live migration was failing. /var/log/neutron/neutron-server.log said the port already existed at the target host.
ERROR neutron.pecan_wsgi.hooks.translation oslo_db.exception.DBDuplicateEntry
default default] create failed (client error): There was a conflict when trying to complete your request.
/var/log/nova/nova-conductor.log Contains:
2024-01-05 04:12:46.063 1787 ERROR nova.network.neutron [instance: 344f91d5-ae4d-4982-80ae-533968eaefec] neutronclient.common.exceptions.Conflict: Binding for port 53f9aa72-ba76-44d0-aa55-a1afe4d20c66 on host hcn03 already exists.
2024-01-05 04:16:14.188 1786 ERROR nova.network.neutron [None req-fce0a500-6cb6-4a27-bc34-aeedfaeed4da 373bfb0a19fe475c8ceffa3768b5af2a f3191ccb29cf4df7b0d2caea424cb6f1 - - default default] [instance: 344f91d5-ae4d-4982-80ae-533968eaefec] Binding failed for port 53f9aa72-ba76-44d0-aa55-a1afe4d20c66 and host hcn03.: neutronclient.common.exceptions.Conflict: Binding for port 53f9aa72-ba76-44d0-aa55-a1afe4d20c66 on host hcn03 already exists.
And sure enough:
openstack port list --host hcn02 |grep "53f9aa72-ba76-44d0-aa55-a1afe4d20c66"
and
openstack port list --host hcn03 |grep "53f9aa72-ba76-44d0-aa55-a1afe4d20c66"
Both show an active port. The following will remove the port binding on the target host after which migration should be possible.
NEUTRON_API_URL=$(openstack endpoint list --service neutron --interface public -c URL -f value)
TOKEN=$(openstack token issue -c id -f value)
curl -X DELETE -H "X-Auth-Token: $TOKEN" ${NEUTRON_API_URL}/v2.0/ports/53f9aa72-ba76-44d0-aa55-a1afe4d20c66/bindings/hcn03